
Session #1: 9th Oct, 1pm ET.
Apart from a few companies where the ML-Ops infrastructure is well developed, most teams need to build their own ML-Ops services. There are end-to-end paid services, but that would bring vendor lock-in. In this working group we are diving into the open source ecosystem of MLOPs products, to figure out which combination of services can resolve the myriads of challenges and needs in an ML project life cycle.
This engagement requires prior experience in python, and git, no prior expertise in ML-Ops is necessary.
Leads / Advisors


❗ Weekly Meeting Time: 1:00-2:00 PM on Sundays
❗ Slack channel [Communication point]: click here to join
Overview:
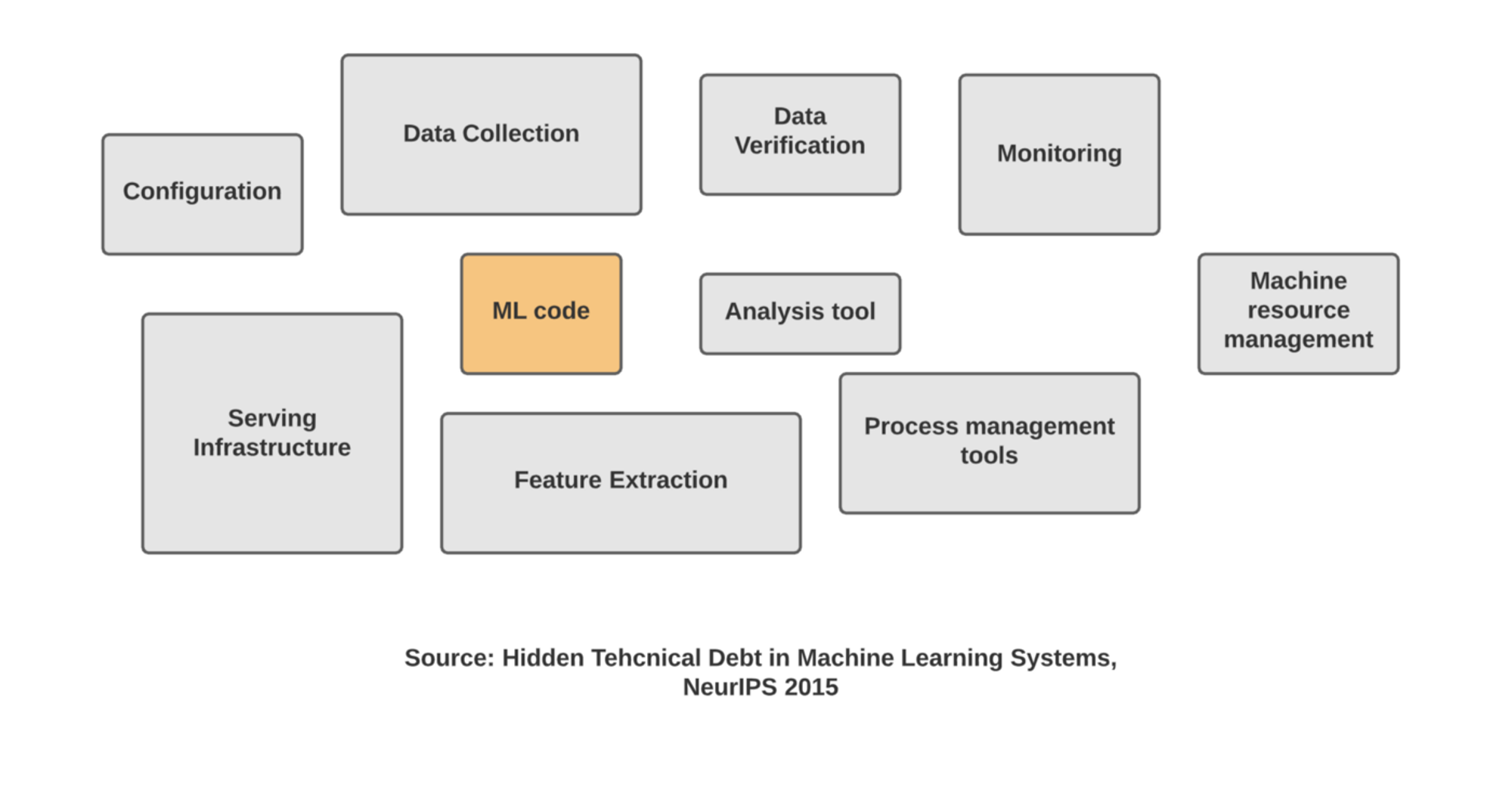
- The current ML-Ops landscape is a mass of different and sometimes overlapping products that are very hard to navigate.
- We will be building a pros and cons list for each element of the ML-Ops ecosystem including orchestration, training, deployment and monitoring and evaluate their strengths and weaknesses. We will focus on implementing these solutions in the AWS environment.
- We will then ensure the pieces are integrated into a coherent solution.
Context
Apart from a few companies where the ML-Ops infrastructure is well developed, most teams need to build their own ML-Ops services. There are end-to-end paid services, but that would bring vendor lock-in. In this working group we are diving into the open source ecosystem of products, to figure out which combination of services can resolve the myriads of challenges and needs in an ML project life cycle.

Goal
Minimum Goal:
- Build an open source end-to-end MLOPs infrastructure with the following necessary features:
- Prepare data (MVP will have tabular, time-series data)
- Productize Code in a docker image.
- Model version and host the model
- Run a toy model through it to ensure it works.
Stretch Goal:
- The end-to-end infrastructure should be the best possible on the current market and potentially have the following additional features:
- Version data
- Changing the model / tracking the experiment.
- Feature drift measurements.
- Store results in a Feature store (model registry)
- Cost minimization (spot instances, etc)
Early Audience Hypothesis
The Target audience include any data science teams who are looking to cut their cost on their ML Operations or have not yet built a sufficient pipeline for their team. In both cases, the output of this project can be used as the exemplary infrastructure for your team with the goal of using the best open source tools available with AWS.
Starting Dataset
Will be added in before session #1
Onboarding [Technical + Domain Knowledge]
Will be added before session #1
Tentative Timeline
Fill out the table below. Rough ballparks are alright - no one gets it 100% right. The total should be ~ 8-10 weeks.
# | Major Milestones | Expected Finish |
1 | Get familiar with our MVP | 2 Weeks |
2 | Tinker & try different things to improve | 6 weeks |
Why join?
Aggregate Intellect hosts one of the most diverse ML communities in the world. Over the course of the working group
- You’ll get an immersion into that community & walk out with some cool new friends.
- Get spotlighted for your efforts on our community website!
- Advance your ML Ops skills by working with a plethora of up and coming open source tools
- Learn how to streamline ML Ops pipelines in a cost efficient manner