
Starts: June 29 - 12 noon ET
In this group, we discuss the basic algorithms and fundamentals of different ML techniques used to personalize services online.
Prior experience using Python is required for this project. We recommend that user’s are also familiar with scikit-learn, Tensorflow/PyTorch, Pandas and Numpy for ML-related modelling tasks. Linear Algebra knowledge is essential as well
Working Group Leads / Advisors


❗ Meeting Link: https://meet.jit.si/WGRecSys
❗ Meeting Time: 12-1 PM ET on Wednesdays (starting the 29th of June)
❗ Slack channel [Communication point]: click here to join
Project Overview
- Practice organizing and structuring big datasets for streamlined use in ML projects
- Train an ensemble of ML classifiers including support vector machines, random forests and collaborative filtering techniques for personalization services
- Examine model performance and robustness when tested against future transactions
- Learn how different algorithms from different fields like GNN, DL and more can be leveraged in personalization models
- Minimal Project Goal: Develop a recommender system on open source datasets Yelp https://www.yelp.com/dataset/download
- Stretch Goal: Quantify the impacts of different models on the dataset utilizing different parts of the input data and building a personalization model that aids in showing users the products that they are really interested in. Determining the offline metrics appropriate for such a project ranging from precision, recall, CTR, accuracy and more. Write up a short article that examines this problem and share your findings
Tentative Project Timeline
# | Major Milestones | Expected time to finish | What to cover |
1 | Get familiar with the project domain | 2-3 weeks | Pre-Reqs + Get familiar with data |
2 | Download & process Yelp Review data | 1 week | |
3 | Test different features and determine the right attributes | 1 week | |
5 | Building offline metrics appropriate | 1 week | |
4 | Develop two ML classifiers | 4 weeks | |
6 | Summarize the difference between the models identifying potential weakness and strengths | 1 week | |
ㅤ | ㅤ | ㅤ | ㅤ |
Tentative Timeline
Session #1 - #3:
- Get to know everyone!
- We will introduce the problem & why it matters.
- Core Team shortlisted. Intensive work begins!
- Core Team will work towards the core problem.
- Will be recognized by AISC at the conclusion of the project!
- [For your portfolio / blog / Social Media].
End of session #3 → Apply to join the Core Team
- Energy & competency are both important, but energy is a little more.
- You can still keep up with the Working Group if you don’t make the Core Team, but only the Core Team will be spotlighted in any complied / published work.
Session #4+ [Tentative length: 1.5 months]
What after?
- If at the end of the 2 month period, there are new areas we’d like to explore, then we may have a follow-up 2 month Working Group! And then another, and so on.
Solution Architecture + Resources
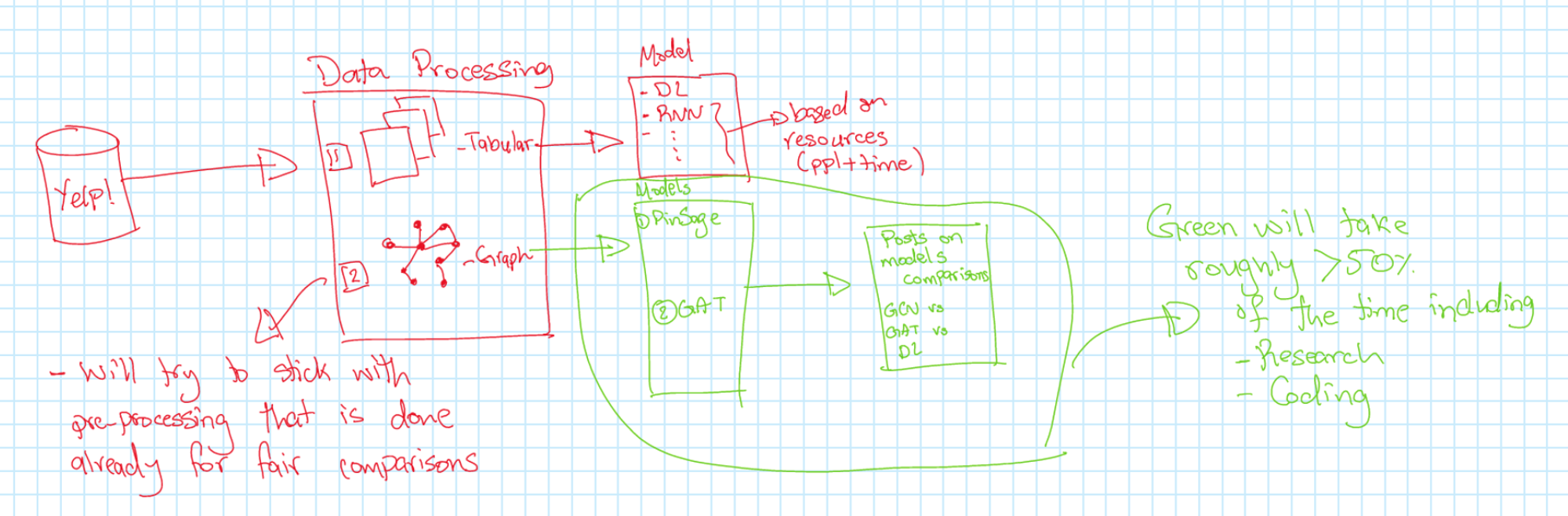
Key Resources
Pre-Reqs (if you need):
Dealing with large datasets Recipe (opt): Click here
Yelp Dataset: https://www.yelp.com/dataset/download
Pre-processing: Click here. The same for each paper. Skim to get some quick intuition.
Graph Recommender Systems: A Survey
Neural Graph Collaborative Filtering (NGCF):
LightGCN:
Self Supervised Graph Learning for Recommendations (SGL):
Model comparison component:
Precision & Recall (more emphasis on Recall):
NDCG
We will write an article on what we learn as we compare the models above. The Core Team will be recognized as co-auhors.
Why join?
Aggregate Intellect hosts one of the most diverse ML communities in the world. Over the course of the working group
- You’ll get an immersion into that community & walk out with some cool new friends.
- Learn how to download and interact with large scale real data in Python
- Advance your ML skills by working on real world problems with classification algorithms of increasing sophistication
Looking forward to meeting everyone in our study group! Please feel free to reach out if you have any questions about the planned project.
To jump in mid-way, just join our Slack channel and introduce yourself!