
Starts: March 24 - 6 pm EDT [$2500 in gifts for participants]
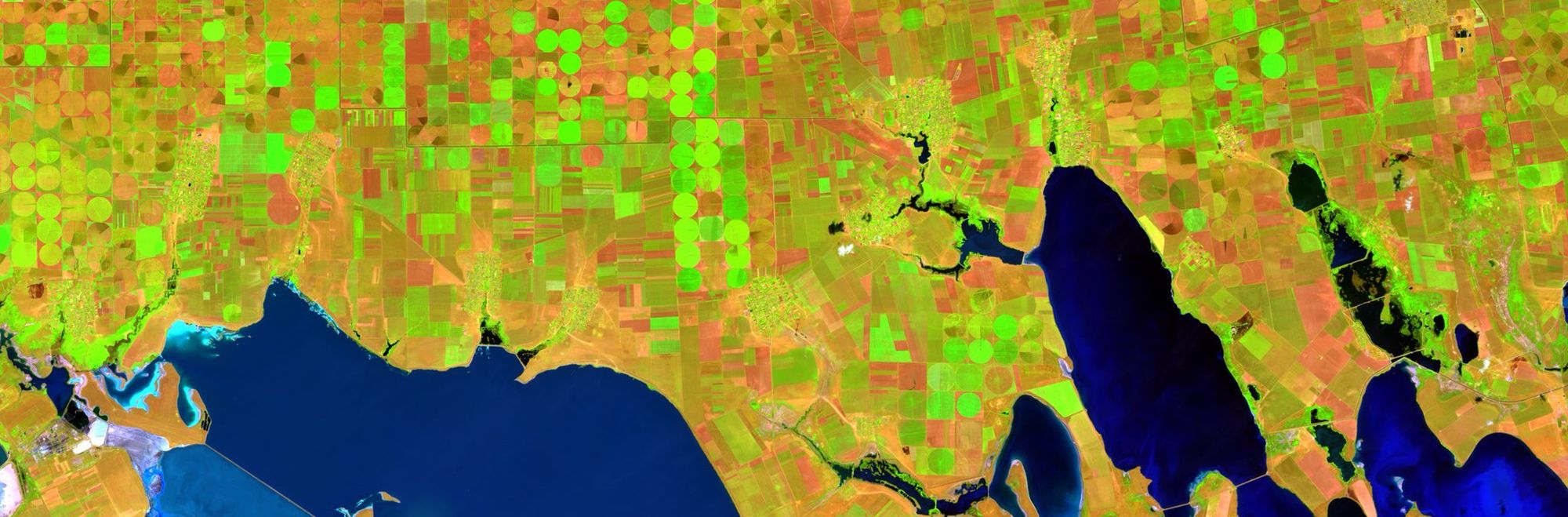
High resolution satellite products provide detailed snapshots of the Earth’s surface. In this work, we examine the capabilities multiple ML techniques trained on Sentinel-2 data to develop an accurate and robust land cover classification algorithm across Canada
Prior experience using Python is required for this project. We recommend that user’s are also familiar with scikit-learn, Tensorflow and Numpy for ML-related modelling tasks. No previous remote sensing knowledge is needed for this project
❗ Meeting Link: https://meet.jit.si/ml-s2-landcover-classification-ai
❗ Meeting Time: 6 PM EDT on Thursdays (starting the 24th of March)
Working Group Leads / Advisors

~ Fraser King | Lead
PhD.c @ University of Waterloo, Canada


Dr Andre Erler | Advisor
~ Senior Climate Scientist at Aquanty
Project Overview
- Learn how to access, download and align remotely sensed Earth imagery (Sentinel-2)
- Practice organizing and structuring big datasets for streamlined use in ML projects
- Train an ensemble of ML classifiers including support vector machines, random forests and convolutional neural networks for land cover classification (using NRCan Land Cover data)
- Examine model performance and robustness when tested against seen/unseen regions across Canada (and practice implementing hyperparameter optimization)
- Analyze the impact of different radar bands and their derived products like NDVI, SWIR and NDMI (ie. various model predictors) on predictive accuracy
- Minimal Project Goal: Develop a ML classifier that can correctly identify multiple land cover types across different Canadian landscapes
- Stretch Goal: Quantify the impacts of spatial resolution on the performance of a CNN land cover classifier. Can training on a mixture of low and high resolution samples provide good predictive accuracy when tested on high resolution images elsewhere? Write up a short article that examines this problem and share your findings
Land Cover Classification Competition ($2500 CAD in prizes!)
- At the end of the 8 week program (ie. on the 20th of May at midnight). We will close submissions for our Land Cover Classification competition.
- This competition will build on all of the skills taught in this course to develop an accurate and robust classifier that takes as input 12 spectral bands (listed below) from Sentinel-2 L2A (the raw bands, no necessary preprocessing) and predicts the set of 19 NRCan 2015 land cover classes, at a resolution of 60 m. I have included an example of what the downloaded S2 data will look like from Sentinel-Hub here: https://i.imgur.com/t6blupG.png
- The best performing model will be decided by testing your classification model against a hidden set of 3 cloud-free images in Canada selected by us (below 60 degrees N) during August (from 2015-2020). Accuracy scores will be derived using scikit-learn’s balanced_accuracy_score metric (https://scikit-learn.org/stable/modules/generated/sklearn.metrics.balanced_accuracy_score.html).
- The expected input for your submitted model will be a Nx12 matrix of float64 where N is the number of pixels being tested and the 12 columns will be the Sentinel-2 spectral bands in this order:
- B01, B02, B03, B04, B05, B06, B07, B08, B09, B11, B12, B8A
- The data we will be testing your model on will be in the form of a 5250000 row dataset (ie. a 2500 x 2100 pixel image (approx. 20 square km) if you wish to maintain the spatial structure of the scene). If you are using a CNN, please mention this and include a code snippet which will reshape the testing data to a 2500 x 2100 matrix before feeding it into your model.
- Your model should output a single Int from 0 to 19 (ie. a land cover class).
- Again, since we are defining this as a standard format, you must adhere to it exactly. If we are unable to test your model against our data, we will be unable to assign it an accuracy score. We will provide a downloadable sample dataset to test on your model and confirm it is working as expected at a later date.
- Deliverables: Please provide a single pickled model .sav file (eg. https://machinelearningmastery.com/save-load-machine-learning-models-python-scikit-learn/) which can easily be loaded. Also a short writeup describing your model structure and how it was trained. If you are including an extra preprocessing code block, include this here as well along with any necessary details.
- Where to submit? Please upload a single .zip file with your team name as the filename to the Dropbox by the deadline: https://www.dropbox.com/request/adwuhmzcQKLBkr53LQoI
- $1500 will be given away in this competition! 1st - $750, 2nd - $350, 3rd - $200, 4th and 5th - $100 each.
- An additional $1000 will be evenly split among all course members who can demonstrate (either through a submitted model in the above competition or some other proof by the 19th of May) that has an accuracy of at least 20% on their own NRCan land cover experiment.
- If you have any questions about the competition, please let us know. Good luck everyone!
- Example notebook for testing your model: https://colab.research.google.com/drive/1Odk9BFvriINUrD8Lma-fQ8up5pKih3ec?usp=sharing
Tentative Project Timeline
# | Major Milestones | Expected time to finish |
1 | Get familiar with the project domain | 2-3 weeks |
2 | Download & process S2/LC data | 1 week |
3 | Develop ML classifiers | 2 weeks |
5 | Out-of-site testing / model parameter optimization | 1 week |
6 | Analyze model predictor importances | 1 week |
Our Journey - Land Cover Classification
Why join?
Aggregate Intellect hosts one of the most diverse ML communities in the world. Over the course of the working group
- You’ll get an immersion into that community & walk out with some cool new friends.
- $2500 in prizes will be awarded to the top performing models at the end of the course when applied to unseen data. See the above section covering these rules in more detail.
- Learn how to download and interact with remote sensing data in Python
- Advance your ML skills by working on real world problems with classification algorithms of increasing sophistication
- Contribute to a study area (land cover classification) which has major impacts to resource management practices, wildlife habitat protection and in advancing our understanding of the Earth’s biophysical systems
Looking forward to meeting everyone in our study group! Please feel free to reach out if you have any questions about the planned project.
The button below will take you to our coordination Slack channel. Just jump in, introduce yourself, and say you wanna join! We’ll try to help bring you up to speed.